Have you ever returned to an AI conversation the next day, asked it to continue where you left off, and watched it confidently claim completion of work that was never actually finished? If you are working on complex projects that span multiple sessions, you have probably experienced the frustration of AI agents that forget everything you discussed yesterday.
This is not just an inconvenience. It is an architecture problem with a systematic solution. In my experience building document processing systems with AI agents, I discovered that conversation memory fails catastrophically for multi-day work, but repository-based persistent context succeeds consistently.
This article expands on the architecture patterns I covered in my video about multi-session AI workflows. You will learn how to implement a five-layer repository structure that makes context survive session boundaries, along with practical forcing functions that ensure agent discipline in consulting documentation before making claims.
The Monday Morning Amnesia Problem

Last Monday morning, I opened my AI conversation and typed "Continue Phase 2 implementation." The agent immediately responded: "Phase 1 is complete. Moving to Phase 2 now."
But Phase 1 was not complete. Not even close.
The previous Friday, I had spent the afternoon designing a document taxonomy feature with the same agent. We created a comprehensive project roadmap with clear phases, wrote a 527-line requirements specification with detailed design decisions, and established taxonomy structures. The agent participated in every step. The context was rich and detailed.
Yet Monday morning, it acted as though none of that work existed.
When I challenged the completion claim, the agent admitted it had not checked if required attributes existed in the actual files. When I asked it to verify the taxonomy structure, it attempted a web search for specifications that were already documented in our project roadmap. It made three false claims before I realized what was happening.
This was not user error. This was session amnesia, and it represents a fundamental architecture gap in how we structure AI workflows.
The stakes are higher than mere inconvenience. Session amnesia leads to implementation drift, where new work contradicts previous decisions. It creates quality degradation as agents make assumptions instead of consulting documented requirements. It wastes tokens through repeated explanations and correction cycles. Most critically, it breaks trust between human and agent, undermining the collaborative potential of AI-assisted development.
Understanding the Core Problem
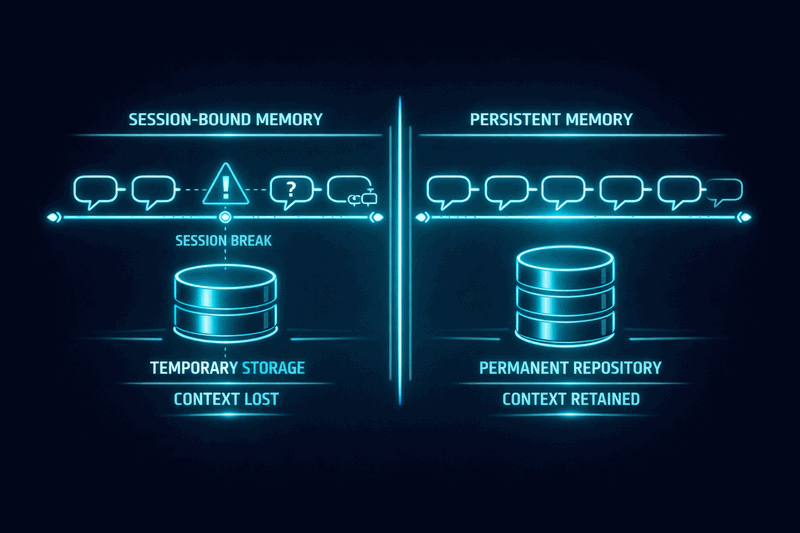
The root issue is that conversation memory is session-bound while complex work is session-spanning. When an AI agent relies solely on conversation history, it loses all context when that session ends. The agent cannot access previous decisions, cannot verify current status against documented requirements, and cannot maintain consistency across implementation phases.
This creates five distinct failure modes that I have observed repeatedly:
Session Amnesia represents complete loss of prior decisions and context when starting new conversations. The agent treats each session as a blank slate, ignoring documented history and established requirements.
False Confidence occurs when agents make claims about completion or status without verification. They assert facts about work state based on assumptions rather than consulting actual files or documentation.
Inefficient Retrieval manifests as agents searching external sources for information that already exists in project documentation. This wastes tokens and often returns less accurate information than internal sources.
Token Waste results from repeated explanations and correction cycles. Without persistent context, agents require re-explanation of requirements, decisions, and current state in every session.
Implementation Drift happens when new work contradicts previous decisions because the agent cannot access the reasoning behind earlier choices. This creates inconsistent implementations that violate established patterns.
These failure modes compound over time. Each session becomes less efficient as context loss accumulates. Quality degrades as consistency breaks down. Trust erodes as false claims multiply.

The Five-Layer Repository Solution
The solution lies in architecture repository structures that substitute persistent context for conversation memory. This approach borrows from TOGAF enterprise architecture patterns, applying organizational memory concepts to AI agent governance.
The five-layer repository structure provides comprehensive context persistence:
Layer 1: Capabilities documents what exists and how it works. These documents describe system features, component behaviors, and functional specifications. They answer the question "what does this do?" with concrete implementation details.
Layer 2: Standards defines how to structure implementations. These documents establish patterns, conventions, and requirements that govern how new work should be organized. They ensure consistency across different implementation phases.
Layer 3: Guides provides step-by-step procedures for common tasks. These documents offer tactical guidance for specific workflows, reducing the need to re-derive approaches in each session.
Layer 4: Plans contains roadmaps, phases, and status tracking. These documents maintain project state across sessions, documenting what has been completed, what is in progress, and what comes next.
Layer 5: Proposals captures design rationale and requirements. These documents preserve the reasoning behind decisions, enabling agents to understand not just what to implement, but why specific approaches were chosen.

Each layer uses a document identification system that enables precise referencing. Capability documents use CAP-NNN identifiers, standards use STD-XXX-NNN patterns, guides follow GUIDE-XXX-NNN conventions, plans use descriptive names like master-plan.md, and proposals use proposal.md or similar descriptive identifiers.
This structure transforms agent behavior from assumption-based to evidence-based. Instead of claiming completion based on conversation memory, agents consult documentation to verify actual state. Instead of searching external sources, they reference internal specifications. Instead of contradicting previous decisions, they access documented rationale.
The effectiveness depends entirely on agent discipline to consult documents before making claims. This discipline can be trained through explicit forcing functions and workflow constraints.

Validation Through Evidence
The repository approach works when implemented correctly. I have direct evidence comparing outcomes with and without repository consultation.
Success Case: Feature Specification Creation
When creating a new feature specification document, I instructed the agent to first read the documentation standard and examine an existing example. The process followed this sequence:
- Agent read STD-DOC-006 (capability architecture standard)
- Agent read CAP-001 (example capability document)
- Agent created CAP-002 following documented structure
The result was a 1091-line capability document with correct structure and all 13 required sections. The metrics were impressive: zero false claims, zero external searches, zero user corrections, and high document quality that fully complied with STD-DOC-006.
Failure Case: Phase Verification
When the agent claimed phase completion without repository consultation, the process broke down completely:
- Agent claimed completion without verification
- Did not read project roadmap for phase definitions
- Attempted web search for taxonomy information
- Did not verify dimension files for required attributes
The metrics revealed the cost: three or more false claims, one unnecessary external search, four or more user corrections, and low token efficiency due to search-correct-re-explain cycles.
The contrast is stark. Repository consultation produces accurate, compliant output with minimal overhead. Conversation memory alone produces false claims, wasted effort, and quality issues.
The key insight from this evidence is that repository effectiveness depends on agent discipline to consult documents before making claims. This discipline can be established through explicit forcing functions in workflow design.

Minimum Viable Implementation
You do not need to implement all five repository layers immediately. Start with two essential documents: a master plan and a proposal.
Master Plan Structure
The master plan serves as project memory, documenting phases, deliverables, and current status. Structure it with clear sections:
- Project Overview: Brief description of goals and scope
- Phase Definitions: What constitutes completion for each phase
- Current Status: What has been completed, what is in progress
- Next Steps: What should happen next and in what order
- Key Decisions: Critical choices that affect implementation
Proposal Structure
The proposal captures requirements and design rationale. Include these elements:
- Requirements: What the system must do
- Design Decisions: How requirements will be met
- Rationale: Why specific approaches were chosen
- Constraints: Limitations that affect implementation
- Success Criteria: How to measure completion
Integration Workflow
The forcing function workflow ensures repository consultation:
- User request: "Continue Phase 2 implementation"
- Agent instruction: "Read project roadmap first, then check actual file state"
- Agent reads master-plan.md to understand phase definitions
- Agent verifies actual implementation status
- Agent reports accurate status before proceeding
This workflow transformed agent behavior immediately. Instead of false completion claims, I received accurate status reports: "Phase 1 incomplete - missing required attributes in dimension files."
The minimum viable approach proves that repository consultation beats conversation memory for complex, multi-session work. Two documents and one forcing function can eliminate the most common failure modes.

Implementation Patterns and Forcing Functions
Successful repository implementation requires more than document creation. It requires workflow patterns that ensure agent discipline in consulting documentation before making claims or taking action.
The Verification First Pattern
Before any status claim, require explicit verification against documented requirements. The pattern follows this sequence: Agent receives request → Agent reads relevant documentation → Agent verifies actual state → Agent reports findings → Agent proceeds with work.
This pattern prevents false confidence by making verification explicit and mandatory. It eliminates the assumption-based responses that create trust issues in multi-session workflows.
The Context Loading Pattern
At the start of each session, require agents to load project context by reading key documents. The pattern includes: Session start → Read master plan → Read recent proposals → Verify current status → Acknowledge context loaded → Begin work.
This pattern ensures that each session begins with full context rather than blank slate assumptions. It recreates the continuity that conversation memory cannot provide across session boundaries.
The Documentation Before Claims Pattern
For any completion or capability claim, require evidence from documentation. The pattern requires: Agent makes claim → Agent cites specific document → Agent quotes relevant section → Agent explains how evidence supports claim.
This pattern transforms agents from assumption-making to evidence-providing. It creates audit trails for decisions and maintains accountability for claims.
These patterns work because they make implicit requirements explicit. Instead of hoping agents will consult documentation, the workflow requires it. Instead of accepting claims without evidence, the process demands verification.
The forcing functions can be implemented gradually. Start with verification requirements for status claims. Add context loading for session starts. Expand to documentation requirements for all significant decisions.
Advanced Repository Patterns
As your repository matures, additional patterns enhance effectiveness for complex, long-running projects.
The Decision Cascade Pattern
Link decisions across repository layers to maintain consistency. When a proposal establishes a design decision, reference it in relevant standards. When standards define patterns, reference them in guides. When guides specify procedures, reference them in capability documents.
This creates decision traceability that prevents contradictory implementations. Agents can follow the cascade from high-level rationale to specific implementation details.
The Status Propagation Pattern
Maintain status consistency across related documents. When a capability is completed, update the master plan. When a phase is finished, update related proposals. When requirements change, update affected standards and guides.
This ensures that status information remains accurate across the entire repository, preventing the drift that occurs when updates happen in isolation.
The Context Inheritance Pattern
New documents inherit context from parent documents. New capabilities reference relevant standards. New guides reference applicable proposals. New phases reference previous phase outcomes.
This creates context continuity that supports agent understanding of how new work relates to existing decisions and implementations.
These advanced patterns become essential as projects grow in complexity and duration. They provide the governance structure that enables AI agents to work effectively on enterprise-scale, multi-month initiatives.

Conclusion
Multi-session AI workflows fail when they rely on conversation memory alone, but succeed consistently when built on repository-based persistent context. The five-layer architecture repository structure - capabilities, standards, guides, plans, and proposals - provides the governance framework that makes context survive session boundaries.
The evidence is clear: repository consultation produces accurate, compliant output with zero false claims and minimal corrections. Conversation memory alone produces false claims, wasted effort, and quality degradation.
Start with the minimum viable implementation: a master plan and a proposal document. Add forcing functions that require verification before claims and context loading before work. Expand the repository as project complexity grows.
The key insight is that agent discipline can be trained through explicit workflow requirements. Instead of hoping AI agents will consult documentation, make consultation mandatory. Instead of accepting claims without evidence, require verification against documented state.
This approach transforms AI agents from assumption-making assistants into evidence-based collaborators. It enables the complex, multi-day projects that represent the future of AI-assisted development.
Watch the video for the complete story of how I discovered these patterns through real project failures and successes: https://www.youtube.com/watch?v=Ac565pmGlY0
What multi-session AI frustrations have you experienced? How do you currently maintain context across sessions? Share your experiences in the comments - understanding common patterns helps refine these architectural solutions.
Resources
Watch the video for the personal stories behind this framework: https://www.youtube.com/watch?v=Ac565pmGlY0
How do you currently handle context persistence in your AI workflows?