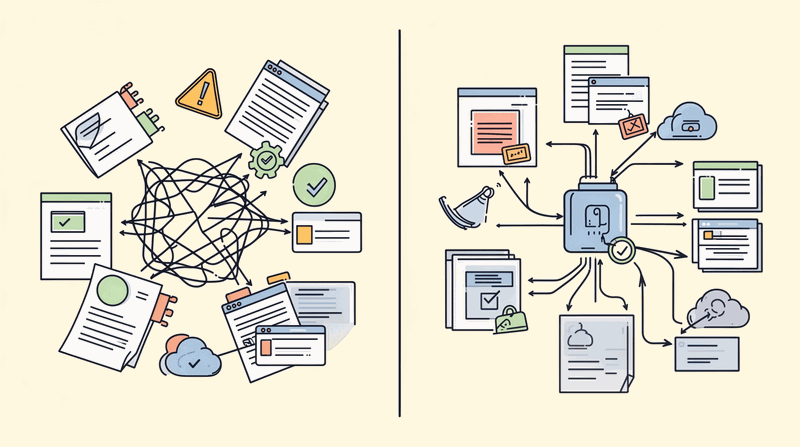
Direct-to-LLM API calls from application code. No gateway. No governance. No observability. If that describes your enterprise, you are running shadow AI.
I discovered this pattern while working with a financial services organization running 15 AI-powered applications across 8 development teams. Each team had independently procured LLM API access, managed their own API keys, and tracked their own costs. The result was monthly AI spend ranging from $12,000 to $47,000 with no predictable pattern and no correlation to business value delivered.
This is the same architectural anti-pattern we solved in the 2000s with database connection pooling and in the 2010s with API gateways. The AI serving layer is evolving from a simple inference endpoint into the enterprise control plane for all AI interactions. Without it, enterprises cannot govern what they cannot see.
The Shadow AI Problem: Direct Calls Without Control
Most enterprise AI applications today call LLM providers directly from application code. No central ai gateway. No governance layer. No observability infrastructure. This creates the same problems we faced when applications called databases directly without connection pooling, or when services called external APIs without an API gateway.
The industry recognizes this shift. Gartner published its first Market Guide for AI Gateways in October 2025, projecting that by 2028, 70% of software engineering teams building multimodel applications will use AI gateways. This category did not exist two years ago. The enterprise AI market reached $114.87 billion in 2026, and Deloitte reports 74% of companies plan to deploy agentic AI within two years.
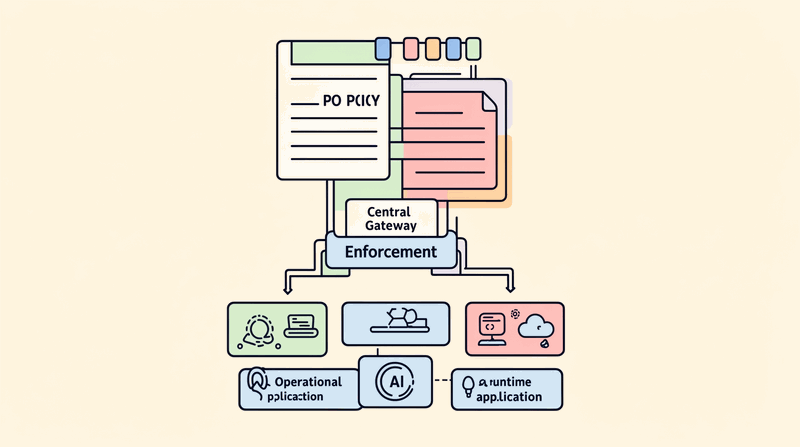
The Serving Layer Is Becoming the AI Control Plane. This is not just about hosting models or proxying inference requests. The ai control plane manages authentication, routing, cost control, security enforcement, and observability across every LLM call in the organization.
Without a centralized control plane, enterprises face vendor lock-in, unpredictable costs, zero failover coverage, compliance blind spots, and no observability across their AI infrastructure. The stakes are higher than most architects realize.
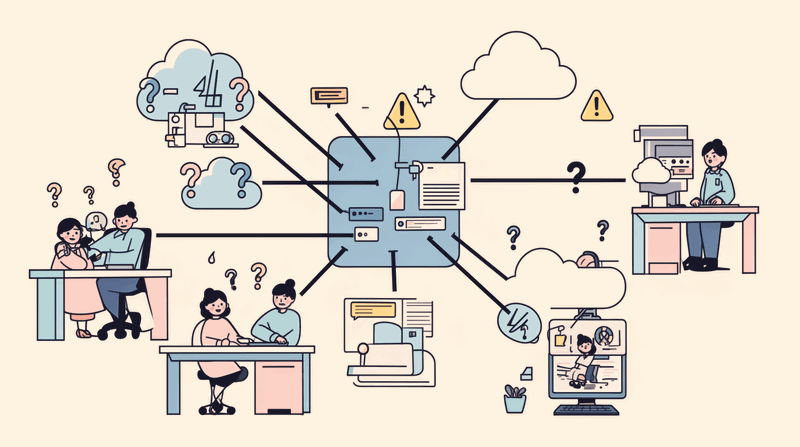
Five Core Functions of the AI Control Plane
The ai gateway evolved beyond simple request forwarding. Modern AI control planes provide five essential enterprise functions that make AI safe, affordable, and operable at scale.
Function 1: Authentication and Authorization
Centralized identity enforcement across all LLM interactions. Team-level access controls, per-user rate limiting, API key management. Without this, any developer with an API key can call any model with any data.
In the financial services organization I mentioned, we discovered developers were sharing API keys through Slack channels. Production applications were using development API keys with no rate limits. The security team had no visibility into who was accessing which models with what data.
The ai gateway provides single sign-on integration, role-based access controls, and centralized API key rotation. Every LLM interaction is authenticated and authorized before reaching model providers.
Function 2: Intelligent Routing and Failover
Route requests to optimal model providers based on cost, latency, capability, and availability. Automatic failover when providers hit rate limits or experience outages. Provider portability without application code changes.
This is the architectural equivalent of a load balancer that understands AI workloads. The gateway evaluates each request against provider capabilities, current pricing, latency requirements, and availability status. When one provider experiences an outage or hits rate limits, traffic automatically routes to alternatives.
The routing intelligence eliminates vendor lock-in. Applications make requests to the gateway using standardized interfaces. The gateway handles provider-specific API formats, authentication methods, and response transformations.
Function 3: Cost Control and Caching
Semantic caching reduces redundant calls by serving identical or near-identical prompts from cache rather than calling LLM providers. Token-level budget enforcement per team, per project, per environment prevents the "$3,000 overnight loop" story that repeats across every enterprise AI team.
In our financial services case study, semantic caching alone eliminated 30% of redundant API calls. The gateway analyzed prompt similarity using embedding models and served cached responses for requests within configurable similarity thresholds.
Budget enforcement operates at multiple levels: per-user daily limits, per-team monthly budgets, per-project cost allocation, and per-environment spending caps. When budgets approach limits, the gateway sends alerts and can automatically throttle or block requests to prevent runaway costs.
Function 4: Security and Content Policy
PII detection and scrubbing before data leaves the enterprise. Prompt injection defense at the gateway layer. Content filtering and safety policy enforcement.
The OWASP Top 10 for LLM Applications (2025) drives at least five of its ten risks through gateway-layer controls: prompt injection, sensitive information disclosure, supply chain vulnerabilities, excessive agency, and model denial of service. The ai security gateway becomes the enforcement point for enterprise security policies.
PII detection scans every outbound request for patterns matching social security numbers, credit card numbers, email addresses, phone numbers, and other sensitive data types. Detected PII can be automatically redacted, tokenized, or blocked based on enterprise policy.
Prompt injection defense analyzes requests for common attack patterns before they reach LLM providers. Content filtering ensures responses meet enterprise safety and compliance requirements.
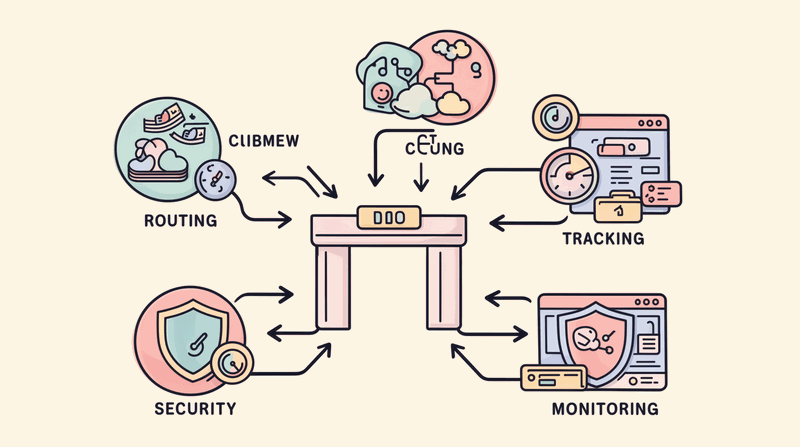
Function 5: Observability and Audit
Centralized logging of every LLM interaction: prompt, response, tokens, latency, cost, model version. Compliance-grade audit trails for regulated industries. Without this level of ai observability, enterprises cannot answer "what data was sent to which model, when, and by whom?"
The observability function captures comprehensive telemetry: request timestamps, user identities, model endpoints, token consumption, response latencies, error rates, and cost attribution. This data feeds into enterprise monitoring systems and compliance reporting tools.
For regulated industries, the audit trail provides immutable records of AI interactions. Financial services organizations need to demonstrate AI decision transparency for regulatory examinations. Healthcare providers must track AI usage for HIPAA compliance. Government agencies require comprehensive audit logs for security clearance reviews.
Real-World Transformation: From Chaos to Control
The organization I worked with implemented a centralized ai gateway as the single point of ingress for all LLM interactions. We started with a proxy pattern to minimize disruption: each team's existing API calls were redirected through the gateway without changing application logic.
The results were immediate. Monthly AI spend stabilized at approximately $18,000, a 62% reduction from the $47,000 peak. Semantic caching eliminated 30% of redundant calls. Budget alerts prevented runaway spend. The security team gained first-ever visibility into AI data flows. The compliance team could produce audit trails for the first time.
Most importantly, the PII detection caught three applications sending customer data to LLM providers without appropriate data processing agreements. These were remediated within the first week of gateway deployment.
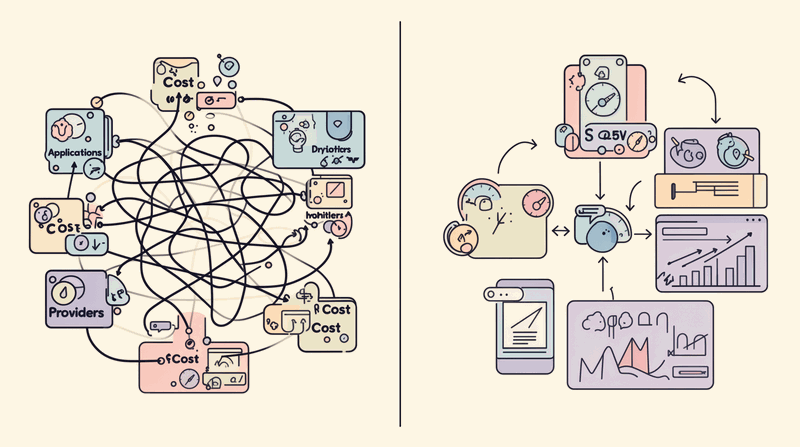
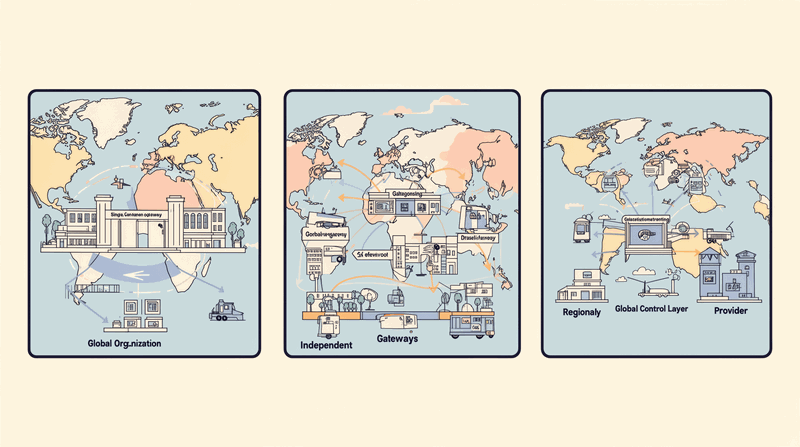
Three Deployment Patterns for Enterprise AI Gateways
The Gartner Market Guide identifies three primary deployment patterns for enterprise ai infrastructure. Each pattern addresses different organizational needs and technical constraints.
Pattern 1: Aggregator (Global Control)
Single gateway instance with global policy enforcement. All AI traffic flows through one centralized control point. This pattern provides maximum governance and observability but may introduce latency for geographically distributed applications.
The aggregator pattern works best for organizations prioritizing governance over latency, with centralized AI teams managing enterprise-wide policies. Financial services and healthcare organizations often choose this pattern for regulatory compliance requirements.
Pattern 2: Proxy (Fast Rollout)
Individual gateways front specific LLM providers with lightweight policy enforcement. This pattern enables rapid deployment with minimal application changes. Teams can start with provider-specific gateways and evolve toward centralized control over time.
The proxy pattern provides immediate visibility and basic cost control without requiring enterprise-wide coordination. Development teams can deploy provider-specific gateways independently while maintaining existing application architectures.
Pattern 3: Composite/Hybrid (Regional + Global)
Regional gateways provide low-latency access while feeding telemetry to a global control layer. This pattern balances governance requirements with performance needs for geographically distributed enterprises.
Regional gateways handle authentication, caching, and routing decisions locally. Global control planes aggregate telemetry, enforce enterprise policies, and coordinate cross-regional intelligence. This pattern supports multinational organizations with local data residency requirements under global governance frameworks.
Connection to AI Governance and Platform Architecture
The ai gateway is where governance becomes enforceable. Governance frameworks decide WHAT AI systems should exist, what risks they carry, and what standards apply. The control plane enforces HOW these decisions operate at runtime.
This connects directly to broader AI platform architecture. The serving layer is one of four platform layers in comprehensive AI infrastructure. While this analysis focuses on the control plane functions, the serving layer operates within compute layers, data layers, and orchestration layers that together enable enterprise AI operations.
The EU AI Act compliance consideration becomes critical here. Article 14 human oversight requirements and comprehensive logging and traceability requirements take full effect August 2026. The control plane is the enforcement point where regulatory requirements become operational controls.
Centralize AI Traffic Before You Govern It. This principle mirrors the API gateway lesson from the microservices era: you cannot apply consistent security, rate limiting, or observability to traffic you do not control. The ai gateway is the enforcement point where architectural governance becomes operational reality.
Implementation Strategy: Start with Visibility
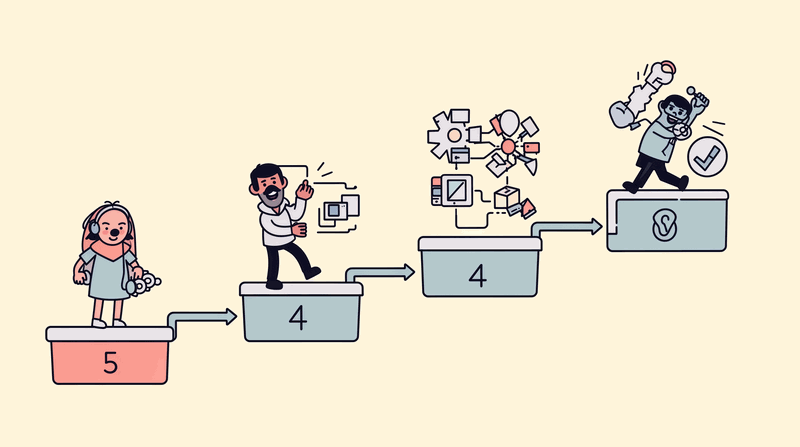
The path to AI control plane implementation follows a proven pattern. Phase 1 focuses on visibility through proxy deployment. Phase 2 adds control through authentication and budget enforcement. Phase 3 implements governance through security policies and compliance controls. Phase 4 optimizes through intelligent routing and advanced caching.
Start with a proxy pattern to gain immediate visibility with minimal disruption. Redirect existing AI traffic through the gateway without changing application code. This provides instant observability into AI usage patterns, cost attribution, and security posture.
The proxy pattern requires minimal coordination across development teams. Each team can deploy provider-specific gateways independently while maintaining existing application architectures. As teams gain confidence with gateway functionality, they can migrate toward centralized aggregator or hybrid patterns.
Most enterprises discover ungoverned AI traffic during the visibility phase. Applications calling LLM providers directly from development environments. Prototype applications using production API keys. Teams sharing API credentials through informal channels. Shadow AI usage that bypassed procurement and security review processes.
The inventory process reveals the scope of AI governance gaps. Count direct-to-provider calls across the organization. Each one represents ungoverned AI traffic that operates outside enterprise controls. The visibility phase quantifies the governance challenge before implementing solutions.
Taking Action: Your AI Gateway Assessment
Inventory your current AI API integrations this week. Count how many direct-to-provider calls exist without an ai gateway. Each one is ungoverned AI traffic that operates outside enterprise security, cost control, and observability frameworks.
Start with a proxy pattern to gain visibility before optimizing. The proxy approach provides immediate value with minimal disruption to existing applications. Teams can continue using familiar APIs while gaining centralized monitoring and control.
The assessment should identify:
- Applications making direct LLM provider calls
- Teams managing independent API keys and billing
- AI usage without centralized cost tracking
- Data flows to LLM providers without security review
- Compliance gaps in AI audit trail requirements
This inventory becomes the foundation for AI control plane implementation. The data drives decisions about deployment patterns, policy priorities, and migration timelines.
The serving layer evolution from inference endpoint to control plane represents the maturation of enterprise AI infrastructure. Organizations that centralize AI traffic through gateway architectures gain the visibility, control, and governance capabilities required for safe, affordable, and compliant AI operations at scale.
Conclusion
The AI serving layer is no longer just about hosting models or proxying inference requests. It has evolved into the enterprise control plane that makes AI safe, affordable, and operable in regulated environments. The five core functions—authentication, routing, cost control, security, and observability—address the fundamental challenges enterprises face when deploying AI at scale.
Organizations running direct-to-provider LLM calls from application code are operating shadow AI infrastructure. Without centralized control, they cannot govern what they cannot see. The AI gateway provides the enforcement point where governance policies become operational controls.
The transformation from cost chaos to control is achievable. Start with visibility through proxy deployment. Inventory your ungoverned AI traffic. Implement centralized authentication and cost controls. Build toward comprehensive governance and compliance capabilities.
The enterprise AI market continues expanding rapidly, with 74% of companies planning agentic AI deployment within two years. The EU AI Act requirements take full effect August 2026. Organizations that implement AI control planes now will be positioned for governed, observable, and compliant AI operations as regulatory and business requirements intensify.
Resources
- Related: AI Enterprise Architecture Explained: Platform, Applications, and Governance
- Related: Generative AI Enterprise Architecture: RAG, Prompt Engineering, and Production Patterns
- Video: Watch on YouTube
Watch the video for the complete story of how one organization transformed from $47K monthly AI chaos to $18K controlled spend with full governance: Watch on YouTube
How many of your AI applications currently call LLM providers directly without a gateway? What would centralized AI cost visibility mean for your organization's AI strategy?