Agentic AI dominates the headlines. Autonomous agents that plan, reason, and execute multi-step tasks capture imagination and investment. But here is the reality most enterprises face: they are still figuring out basic generative AI architecture.
Your RAG prototype works brilliantly in the demo. Your chatbot impresses stakeholders in the pilot. Then production happens. Inconsistent outputs. Ungoverned generation. Costs spiraling beyond budgets. The problem is not the large language model - it is the missing architecture.
This guide covers the production patterns you need for generative AI systems that actually work: RAG three-layer architecture, prompt-as-code discipline, model serving patterns, GenAI governance, and deployment strategies. Master these foundations before attempting agentic autonomy.
The GenAI Architecture Gap
Most organizations implement generative AI the same way they built their first web applications in 1995: ad-hoc patterns that work for prototypes but fail at scale. Prompts embedded as strings throughout codebases. RAG implemented as monolithic black boxes. No governance beyond "hope the model behaves."
In my experience working with government agencies and financial institutions, this approach creates a predictable failure pattern. The pilot succeeds because controlled data, limited users, and manual oversight mask architectural problems. Production exposes every missing pattern: retrieval latency, context window limits, hallucination risks, cost overruns.
The solution is not more sophisticated models. It is enterprise architecture patterns specifically designed for generative AI systems. Three-layer RAG architecture that enables independent optimization. Prompt-as-code discipline that applies software engineering to prompts. Model serving patterns that treat LLMs as infrastructure requiring production engineering.
RAG Three-Layer Architecture
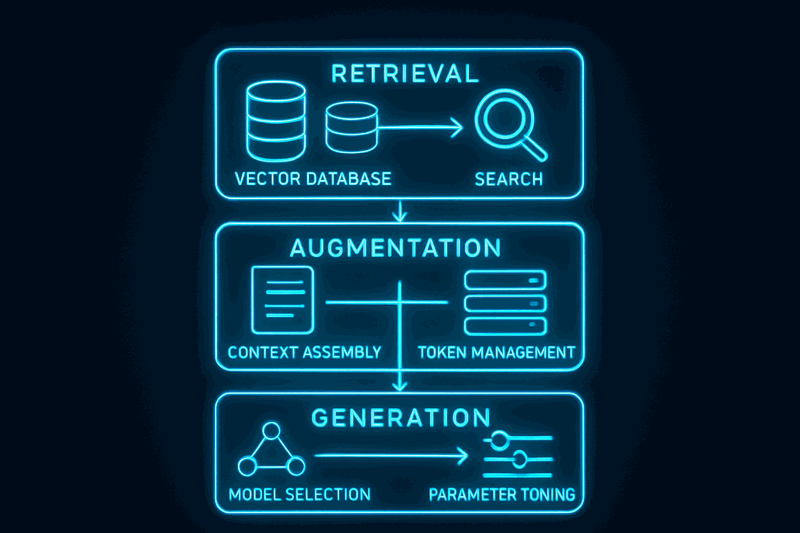
RAG is not a single monolithic pattern. It is three-layer architecture: Retrieval, Augmentation, and Generation. Understanding these layers enables independent optimization, precise problem diagnosis, and production-scale deployment.
Retrieval Layer: Finding Relevant Information
The retrieval layer handles semantic search across your knowledge base. Vector databases store document embeddings. Chunking strategies determine how documents split into searchable segments. Caching reduces latency and costs for repeated queries.
Key decisions: Which embedding model (sentence transformers vs provider embeddings)? What chunking strategy (fixed size vs semantic boundaries)? How much overlap between chunks? Which vector database solution for your scale?
Production pattern: Implement retrieval caching. Similar queries reuse cached results instead of re-computing embeddings and vector searches. This single optimization reduced our costs by 60% in production.
Augmentation Layer: Context Assembly
The augmentation layer combines retrieved chunks with user prompts into context that fits the model's token limits. This involves ranking retrieved chunks by relevance, assembling context within token budgets, and adding metadata like source attribution.
Critical challenge: Context window management. Latest generation models support 128K+ tokens, but costs scale linearly with context length. Smart context assembly keeps only the most relevant information while maintaining quality.
Production pattern: Token budget allocation. Reserve tokens for user prompt (20%), system instructions (10%), output space (20%), retrieved context (50%). Monitor token usage and optimize chunk selection based on relevance scores.
Generation Layer: Model Selection and Tuning
The generation layer selects appropriate models for tasks and tunes parameters for consistent outputs. Different tasks require different models: simple questions work with smaller models, complex reasoning needs larger models.
Parameter tuning affects output consistency. Temperature controls randomness (lower = more deterministic). Top-p controls vocabulary selection. Max-tokens limits response length. These parameters must be tuned for your specific use case, not generic benchmarks.
Production pattern: Model routing based on query complexity. Route simple factual questions to cost-effective models. Route complex reasoning tasks to premium models. Implement automatic fallback when primary models are unavailable.

I learned this architecture the hard way. Our first RAG implementation at a government agency was ad-hoc. Retrieval, augmentation, and generation were three separate components without recognizing they were distinct architectural layers. The system worked brilliantly for our 100-document pilot. Production required 100,000 documents.
Performance degraded catastrophically. Retrieval took 30 seconds because we had no chunking strategy. Augmentation hit token limits because we had no context management. Generation gave inconsistent answers because we had no parameter tuning. The team could not understand which layer was failing because we had no architecture distinguishing retrieval versus augmentation versus generation.
Introducing RAG three-layer architecture transformed both performance and engineering capability. Production performance: retrieval under 2 seconds with chunking and caching, augmentation handles 100K documents with smart context assembly, generation consistent with tuned parameters. More importantly, the team now has architecture to diagnose issues: "retrieval layer slow" versus "augmentation hitting token limits" versus "generation quality poor" become precise engineering problems instead of vague "RAG is broken."
Prompt Engineering as Architectural Discipline
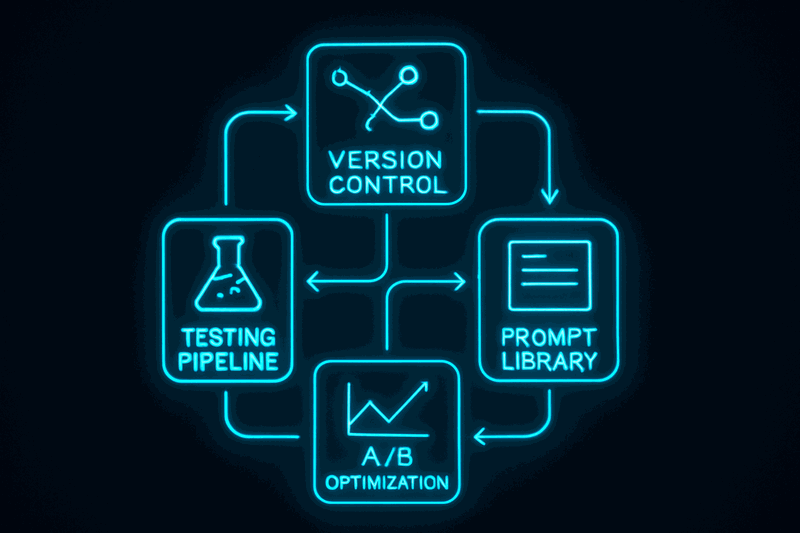
Prompts are code, not configuration strings. Treating prompts like code enables the same engineering discipline that makes software reliable: version control, regression tests, performance measurement, reusable components.
Prompt-as-Code Framework
Version control stores prompts in repositories with semantic versioning. Track changes with commit messages. Create branches for prompt experiments. Merge successful improvements back to main.
Testing creates regression test suites for prompts. Define expected outputs for known inputs. Run tests before deploying prompt changes. Catch breaking changes before they reach production.
Optimization uses A/B testing for prompt variants. Split traffic between prompt versions. Measure performance metrics: error rates, quality scores, task completion. Keep winning variants, discard failing ones.
Libraries extract reusable prompt components. System prompts define model behavior. Few-shot examples provide output formatting. Output formatters ensure consistent structure. Compose prompts from components instead of duplicating patterns.
Production Impact: 40% Error Reduction
A financial services chatbot deployed to production with prompts embedded as strings throughout the codebase. Developers modified prompts directly to improve responses. Three months into production, chatbot quality degraded. Nobody knew which prompt changes helped versus hurt because prompts were not versioned.
The challenge was complete lack of engineering discipline. Could not roll back to known-good prompts because no version history. Could not test prompt changes before deployment because prompts were strings in code, not versioned artifacts. Could not measure prompt performance because no A/B testing framework. Compliance wanted audit trails of prompt changes but prompts were scattered across 40 files.
Implementing prompt-as-code discipline solved all these problems. Prompts became versioned artifacts in a git repository with semantic versioning. Regression testing framework provided test suites for prompts with expected outputs. A/B testing measured which prompt variants performed better. Prompt library enabled reusable components with composition patterns.
Error rate decreased 40% within two months. Root cause: most prompt changes actually hurt quality, but the team had no data to know which changes to keep versus discard. Prompt versioning plus testing enabled data-driven optimization instead of guess-and-check. Compliance got audit trails. Developers got reusable prompt components instead of copy-paste duplication.

Think about prompts like recipes. Ad-hoc prompts are like cooking without recipes: tasty but inconsistent, cannot replicate, hard to teach others. Prompt templates are written recipes: consistent results, reproducible, shareable. Prompt versioning creates recipe iterations where version 1.0 is good, version 2.0 is better, version 3.0 is best so far. Prompt testing validates that known good ingredients and steps produce expected results. Prompt optimization A/B tests recipe variations to keep the better performing one.
Everyone understands recipes are better than ad-hoc cooking for consistent results. Yet teams treat prompts as ad-hoc strings instead of versioned recipes. Professional chefs use standardized recipes with testing and iterations. Professional engineers should use versioned prompts with testing and optimization.
Model Serving Architecture
Model serving architecture provides infrastructure patterns for deploying LLMs at production scale. Direct LLM API calls work for prototypes but fail at production scale: no failover when providers have outages, no caching so every request costs money, no version control so model updates break production, no routing so you cannot switch models based on task complexity.
Infrastructure Patterns
API design defines request and response contracts. Choose streaming for real-time applications, batch for bulk processing. Implement rate limiting to prevent abuse. Add authentication with token-based access control.
Load balancing routes different tasks to appropriate models. Simple questions go to cost-effective models. Complex reasoning tasks go to premium models. Implement failover so when primary providers are down, traffic automatically routes to secondary providers.
Caching implements prompt caching for similar queries and response caching for deterministic outputs. Cache invalidation determines when to refresh cached responses. This optimization alone can reduce costs by 60% in production.
Version management uses blue-green deployment where new model versions deploy alongside old versions, with traffic gradually shifted. Canary releases send 10% of traffic to new models first. Automated rollback triggers when quality gates detect degradation.
Monitoring tracks latency for response times, cost per request for token usage, quality metrics for hallucination rates and user satisfaction, and error rates for system reliability.
GenAI Governance Patterns

GenAI-specific governance addresses unique challenges that traditional software governance does not handle: output validation for hallucination detection, content filtering for inappropriate responses, compliance controls for audit trails, and cost governance for token budget management.
Output Validation
Hallucination detection implements fact-checking against trusted sources. Quality scoring measures output accuracy and relevance. Confidence thresholds determine when to flag responses for human review.
Content filtering scrubs personally identifiable information from inputs and outputs. Inappropriate content detection prevents harmful or offensive responses. Source attribution ensures generated content cites original sources.
Compliance Controls
Audit trails track who generated what content when. Data lineage shows which sources contributed to generated outputs. Version control maintains history of model and prompt changes.
Cost governance implements token budgets to prevent runaway costs. Rate limiting controls request frequency per user or application. Usage monitoring provides visibility into spending patterns across teams and projects.
These governance patterns integrate with the standards frameworks I covered in my video on RFC 2119 standards for AI systems. MUST requirements become automated validation rules. SHOULD recommendations become monitoring alerts. MAY options become configurable features.
Production Deployment Patterns

Model updates are deployments, not upgrades. LLM providers optimize for general benchmarks, not your specific use case. Never deploy model updates to 100% production traffic - always canary first.
Canary Deployment Strategy
Deploy new models to 10% of traffic first. Monitor quality metrics: hallucination rates, user satisfaction scores, task completion rates. Compare performance to baseline model. Implement automated quality gates that trigger rollback if metrics degrade.
Gradual rollout increases traffic allocation: 10% to 25% to 50% to 100% over two weeks if quality holds. Each stage requires quality validation before proceeding.
Rollback strategies activate when quality degrades. Model hallucinations increase beyond thresholds. User satisfaction drops below acceptable levels. Automatic rollback to previous version prevents widespread production impact.
Monitoring and Incident Response
Monitoring dashboards track latency metrics, cost per request, quality scores, and error rates. Alert thresholds notify teams when metrics exceed acceptable ranges.
Incident response handles GenAI failures: inappropriate outputs in customer-facing applications, hallucinations in business-critical decisions, cost overruns from runaway token usage.
An enterprise RAG system serving thousands of internal users provides a perfect example. The LLM provider released a new model version promising 20% better quality and 30% faster inference. The team planned immediate production rollout to capture benefits.
New model performed excellently in test environment. Deployed to 100% production traffic on Friday afternoon. Monday morning brought 200 support tickets: model was hallucinating confidently incorrect answers, especially for domain-specific questions. Quality was actually worse than previous model for specialized enterprise content. Full rollback required, but 72 hours of bad answers had already been delivered to users.
Implementing canary deployment patterns prevented this scenario for future updates. Next model update used canary deployment: detected 15% increase in hallucination rate at 10% traffic. Automatic rollback prevented production impact. Investigation revealed new model needed different parameter tuning for domain-specific content. Tuned parameters, re-ran canary, quality improved 10% versus baseline, gradual rollout successful.

From GenAI to Agentic AI
Generative AI is reactive generation: you provide a prompt, it generates a response. Agentic AI is proactive autonomy: it plans multi-step tasks, uses tools, adapts based on feedback.
The evolution path is clear: master RAG architecture plus prompt engineering plus governance, then add planning plus tool use plus memory to create agentic systems. This is natural progression, not a technological leap.
GenAI foundations enable agentic capabilities. RAG three-layer architecture provides the knowledge retrieval that agents need for informed decisions. Prompt-as-code discipline creates the instruction templates that agents use for consistent behavior. Model serving patterns provide the infrastructure that agents require for reliable execution. GenAI governance establishes the safety controls that agents must operate within.
Without solid GenAI foundations, agentic systems become ungoverned autonomous processes that can cause significant damage. With proper GenAI architecture, agentic systems become powerful extensions of existing patterns.
Implementation Roadmap
Start with RAG three-layer architecture for your next GenAI project this quarter. Define your retrieval layer: choose vector database solution, implement chunking strategy, add caching for performance. Design your augmentation layer: implement context assembly, manage token budgets, add source attribution. Configure your generation layer: select appropriate models, tune parameters, format outputs consistently.
Measure before and after performance. Compare ad-hoc RAG implementation metrics - latency, cost, quality - to architected RAG with production patterns. Document the improvement in precise numbers, not subjective assessments.
Implement prompt-as-code discipline for consistency and optimization. Version control your prompts. Create regression tests. A/B test improvements. Build reusable prompt libraries. Apply the same engineering discipline to prompts that you apply to application code.
Deploy with canary patterns and monitoring. Never update models to 100% traffic immediately. Always test with small traffic percentages first. Implement automated rollback when quality degrades. Monitor costs, latency, and quality continuously.
Conclusion
Generative AI architecture requires the same engineering discipline as any production system: layered architecture for independent optimization, version control for consistent deployments, testing for quality assurance, monitoring for operational visibility, governance for compliance and safety.
RAG three-layer architecture enables precise diagnosis and optimization. Prompt-as-code discipline applies software engineering to prompts. Model serving patterns treat LLMs as infrastructure requiring production engineering. GenAI governance addresses unique challenges of generative systems. Production deployment patterns prevent model update failures.
Master these patterns before attempting agentic autonomy. They provide the foundation that makes autonomous agents safe, reliable, and effective.
Resources
- Video: Watch on YouTube
Watch the video for the complete implementation stories and visual diagrams: Watch on YouTube
What is your biggest challenge with GenAI in production - retrieval performance, prompt consistency, or model serving reliability?