If you have deployed an AI agent and wondered why it confidently executes the wrong plan, the answer lies in a single number: 12%. This is not a configuration problem or a prompting issue. It is a fundamental architectural constraint that every enterprise architect working with agentic AI must understand.
Kambhampati's research team at ICML 2024 demonstrated that LLMs achieve approximately 12% plan correctness when operating autonomously on standard planning benchmarks. Yet organizations are racing to deploy agentic AI systems without grasping this limitation. The gap between "AI agent demos" and "AI agent production" is largely explained by this finding.
This article expands on the research implications and provides the architectural patterns that successful agentic AI implementations use to work around this constraint. If you are evaluating AI agents for enterprise deployment, this data will reshape your approach.
The System 1 vs System 2 Reality of LLMs
The 12% finding makes perfect sense when you understand what LLMs actually do. Following Kahneman's dual-process theory, LLMs operate as System 1 processors: fast, pattern-matching, producing outputs in constant time per token. They lack System 2 capabilities: deliberate reasoning, planning with subgoal decomposition, and self-verification.
From a pure engineering perspective, a system that produces the next token in constant time cannot be performing principled combinatorial search. LLMs excel at pattern recognition and language generation because these are System 1 tasks. They struggle with planning because planning requires System 2 reasoning.
This is why the "just prompt it harder" approach to agentic AI architecture hits diminishing returns. You cannot prompt System 1 into becoming System 2. The architectural response is not better prompts but better scaffolding: structured verification, external feedback loops, and deterministic gates that validate LLM-generated plans before execution.
The implications for enterprise ai agents are immediate. Every autonomous planning task that relies solely on LLM reasoning is building on a foundation that fails 88% of the time without external verification.
The Verification Scaffolding That Actually Works
The breakthrough insight from recent AI agent reasoning research is not that LLMs get better at planning. It is that successful approaches scaffold external verification around the LLM core. Three patterns demonstrate this consistently.
Tree of Thoughts (Yao et al., NeurIPS 2023 Oral) improved Game of 24 from 4% to 74% success rate by enabling exploration of multiple reasoning paths with self-evaluation and backtracking. The key insight: structured search with even limited exploration dramatically outperforms increasing the number of independent attempts. Even best-of-100 Chain of Thought samples only reached 49%, confirming that structured search beats brute-force sampling.
Reflexion (Shinn et al., NeurIPS 2023) achieved 91% pass@1 on HumanEval coding benchmark, surpassing GPT-4's baseline of 80%. This was accomplished through verbal self-reflection stored in episodic memory buffer, without any weight updates. Agents that reflect on failures and store lessons improve without changing the underlying model.
ReAct (Yao et al., ICLR 2023) interleaves thought-action-observation steps, allowing external environment feedback to guide reasoning. Chain of Thought prompting (Wei et al., NeurIPS 2022) established the foundational reasoning pattern.
The pattern across all successful approaches: they scaffold verification around the probabilistic core. None of them make the LLM better at planning. They make the system around the LLM compensate for its planning limitation.
Real-World Verification in Practice
I encountered this limitation directly when an enterprise deployed an AI agent to triage and route customer complaints across five department queues. Initial demo performance was impressive: the agent correctly handled straightforward complaints with high accuracy.
Complex complaints involving multiple issues were consistently misrouted. The agent pattern-matched on prominent keywords rather than reasoning about complaint structure. It routed a "billing error during service outage" to billing (keyword match) when the root cause was service infrastructure (requiring engineering). Misrouting rate on complex cases was approximately 40%. Each misroute added 2-3 days to resolution time and generated customer escalations.
The solution was verification scaffolding: the agent proposes routing decision with reasoning trace, a deterministic rules engine validates the routing against complaint taxonomy, and if validation fails the agent re-evaluates with rules engine feedback. The rules engine was not AI; it was a decision table encoding routing logic that the organization had refined over years.
Misrouting on complex cases dropped from approximately 40% to under 5%. The LLM was still generating routing proposals (its strength: understanding natural language complaints). But the verification layer caught the planning failures before they reached the customer. The LLM did not get better at planning. The system around the LLM compensated for its planning limitation.
The LLM-Modulo Framework for Production Architecture
The architectural implication is clear: every agentic ai enterprise system needs a verification layer that is not the LLM itself. Self-verification is also a form of reasoning, and LLMs struggle with it (Stechly et al., 2024).
Kambhampati's LLM-Modulo Framework provides the architectural pattern: combine LLM strengths with external model-based verifiers in tight bidirectional interaction. The LLM generates candidates; external verifiers validate them. This is not a theoretical framework but a practical architecture pattern.
For production deployment, define deterministic verification gates at every planning step. Use the LLM for generation, not for validation. Trust the output only after external confirmation. The verification layer can leverage existing enterprise systems: rules engines, constraint solvers, domain models, test suites.
This connects directly to foundational architecture patterns. Architecture repositories provide the verification context the LLM cannot generate on its own. Standards with normative language create verification criteria. Forcing functions ensure the AI consults documentation before acting. The repository, the standards, and the forcing functions become the verification scaffolding around the agentic ai core.
Gartner predicts 40% of enterprise applications will embed AI agents by end of 2026, up from less than 5% in 2025. By 2028, 70% of software engineering teams building multimodel applications will use AI gateways (verification and governance infrastructure) to improve reliability. The verification layer is becoming a market category.
Implementation Patterns for Verification Gates
The practical application of llm verification requires specific implementation patterns. Each planning step needs a deterministic checkpoint that validates the LLM-generated plan against known constraints before proceeding to execution.
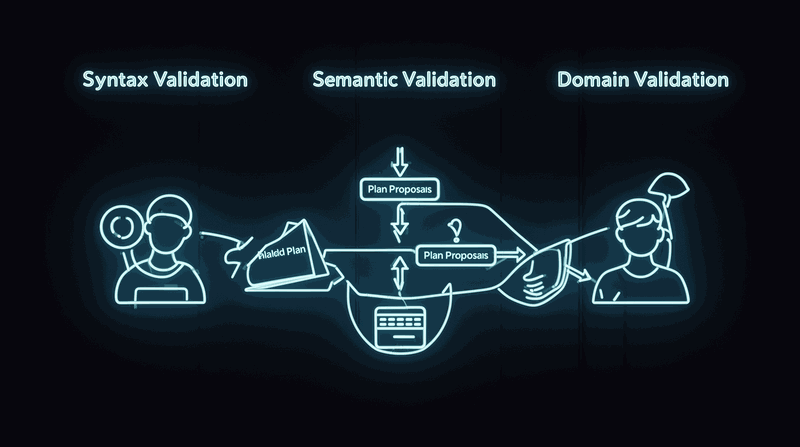
Start with constraint validation. Define the rules, boundaries, and requirements that any valid plan must satisfy. Encode these as deterministic checks: schema validation for structured outputs, business rule engines for domain constraints, test suites for functional requirements. The LLM proposes; the constraint validator confirms or rejects.
Add feedback loops. When verification fails, provide the LLM with specific failure information: which constraint was violated, what the expected format should be, what business rule was broken. This enables the LLM to revise its proposal based on concrete feedback rather than generating entirely new attempts.
Implement progressive verification. Start with simple syntactic checks (format, structure, required fields) before moving to semantic validation (business rules, domain constraints). This catches obvious errors early and reserves expensive domain validation for plausible candidates.
Consider verification caching. Store successful plan patterns and their verification results. When the LLM generates similar plans, reference the cached validation to reduce verification overhead. This builds a knowledge base of verified patterns that improves system performance over time.
The key insight: verification is not a bottleneck but an enabler. Without verification, you have a 12% foundation. With verification scaffolding, you have a production-ready agentic ai architecture.
The Economics of Verification vs Failure
Understanding the economics makes the verification investment obvious. Consider the cost structure of unverified agentic AI versus verification-scaffolded systems.
Unverified systems fail 88% of the time on complex planning tasks. Each failure requires human intervention: investigation time to understand what went wrong, correction time to fix the outcome, and customer impact from delayed or incorrect actions. For the complaint routing system, each misroute added 2-3 days to resolution time and generated escalations that consumed additional support resources.
Verification systems have upfront implementation cost: building the verification logic, integrating with existing systems, and testing the verification gates. But they prevent the cascade of failure costs. The 40% to 5% misrouting improvement eliminated hundreds of hours of investigation time and significantly reduced customer escalations.
The verification logic often already exists in your organization. Business rules engines, domain models, and constraint systems represent years of accumulated domain knowledge. Agentic AI verification leverages these existing assets rather than replacing them.
From a risk management perspective, unverified agentic AI in production represents unlimited downside with bounded upside. Verification scaffolding inverts this: bounded implementation cost with unlimited upside from reliable autonomous operation.
Conclusion
The 12% autonomous plan correctness finding is not an indictment of LLMs but a clarification of their proper architectural role. LLMs excel at System 1 tasks: pattern recognition, language understanding, and candidate generation. They struggle with System 2 tasks: multi-step planning, constraint satisfaction, and verification.
Every successful agentic ai pattern works by scaffolding verification around the probabilistic core. Tree of Thoughts, Reflexion, and ReAct all improve performance through external verification, not through better LLM prompting. The architectural lesson is consistent: use LLMs for generation, external systems for validation.
For architects deploying agentic AI, audit your current systems this week. For each agent, ask: "Where is the verification layer? Is the LLM validating its own plans, or is there an external verification system?" If the LLM is both planner and validator, you have a 12% foundation.
The comprehensive framework for production agentic ai architecture covers 15 architectural pillars beyond verification scaffolding. But verification scaffolding is the foundation that makes everything else possible. Without it, you are building on statistical quicksand.
Watch the video for the personal stories behind this framework and the detailed research implications: Watch on YouTube
What verification patterns have you implemented in your agentic AI systems? Have you experienced the 12% problem in your own deployments?
Resources
- Video: Watch on YouTube
- Related: Architecture Repository as AI Context
- Related: Standards That AI Can Follow
- Related: Forcing Functions for AI Documentation
The data is clear: LLMs cannot plan reliably without verification scaffolding. The question is not whether to implement verification but how quickly you can build it into your agentic AI architecture.